python의 selenium을 이용하여 웹 페이지의 이미지를 크롤링하는 방법 5편입니다.
파이썬 셀레니움 크롤링 (4) : while문을 이용하여 스크롤 끝까지 내리기
python의 selenium을 이용하여 웹 페이지의 이미지를 크롤링하는 방법 4편입니다. 파이썬 셀레니움 크롤링 (3) : 네이버에서 이미지 검색하기 python의 selenium을 이용하여 웹 페이지의 이미지를 크롤링
bom-b.tistory.com
(4)편에서는 스크롤을 내려서 이미지를 로드하는 방법을 알아보았으며
(5)편에서는 이미지를 찾아 다운로드 받는 코드를 적용시켜 보겠습니다.
- driver.find_element().click() 코드 작동안됨 오류!
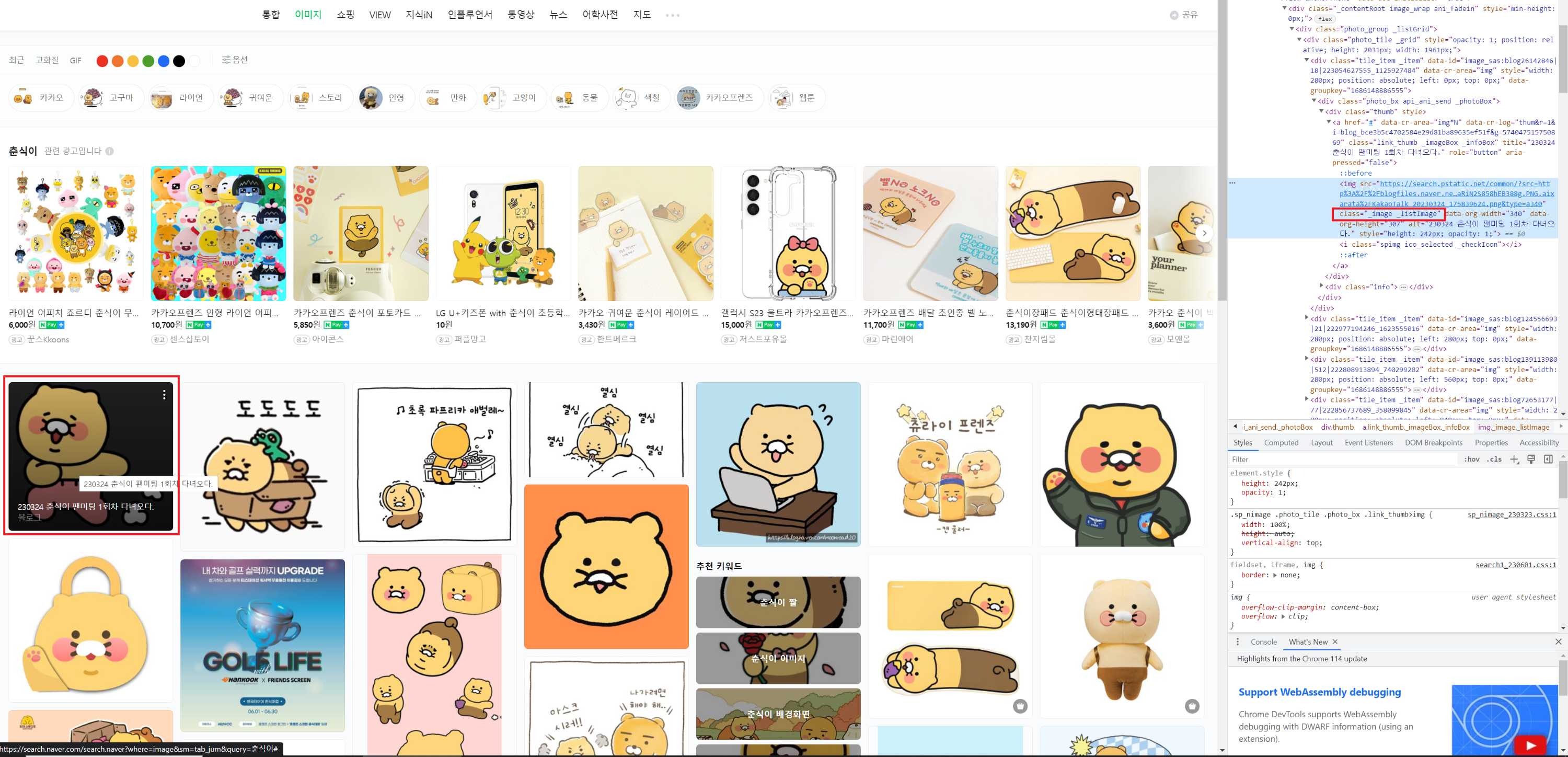
빨간색 박스로 선택한 사진의 class를 알아내서 저것을 선택하고 클릭하는 코드를 먼저 작성해보겠습니다.
사진의 class는 _image _listImage입니다.
driver.find_element(By.CSS_SELECTOR, "._image._listImage").click()코드는 간단합니다. 그런데 문제가 발생했습니다.
모든 참고자료에서는 코드를 이렇게만 알려주고 있었는데요,
어떻게해도 코드가 작동하지 않았습니다.
찾는 요소를 바꾸거나 입력하는 키를 바꾸어도 묵묵부답이라 답답했습니다.
연구해보니 페이지가 로드 되기 전에 이미지를 찾는 코드가 작동해서 이미지를 찾지 못해 동작하지 않는 것이었습니다.
아무도 이런 문제가 발생했다는걸 보지 못해서 혼자 찾느라 애를 좀 먹었습니다.
WebDriverWait를 이용하여 코드를 다시 작성하였습니다.
이 객체는 특정 조건이 충족될 때 까지 대기하게 만듭니다.
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# 이미지 요소가 나올 때 까지 대기할 시간(초)
wait_time = 10
# WebDriverWait 객체 생성
wait = WebDriverWait(driver, wait_time)
# 이미지 요소가 나타날 때까지 대기
images = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "._image._listImage")))
# 이미지가 존재하는 경우
if len(images) > 0:
image[0].click()
한줄씩 해석해보겠습니다.
이미지 요소가 나타날때까지 대기하는 시간을 10초로 설정합니다.
크롬으로 지정한 driver가 wait_time변수로 지정한 시간만큼 대기하도록 합니다.
wait.until() 메서드를 사용하여 이미지 요소가 나타날 때까지 대기합니다. EC.presence_of_all_elements_located() 조건은 지정된 CSS 선택자에 해당하는 모든 요소를 확인합니다. 그리고 images 변수에 찾은 이미지 요소들을 할당합니다.
images리스트에 이미지 요소 개수가 0보다 크면 아래의 코드 블럭을 실행합니다.
images리스트의 첫번째 요소를 클릭합니다.
남들은 한 줄로 구현할 수 있는 코드를
개발환경이 달라 이미지 로딩이 오래걸려 훨씬 더 복잡한 코드로 구현했습니다.
코드는 훨씬 복잡한데 결과물이 같습니다.
하지만 이 과정을 통해 오히려 코드가 간결해야만 좋은 것이 아니라
어떤 환경에서도 작동할 수 있게끔 방어 로직을 생각해야 한다는 것을 알게됩니다.
- urllib.request.urlretrieve을 이용하여 이미지 다운로드
위의 코드에 살을 조금 더 붙여 저 이미지를 선택했을 때 나오는 큰 이미지를 다운 받는 코드를 작성해보겠습니다.

이번엔 XPath를 활용하여 코드를 작성해보았습니다.
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import urllib.request
import urllib
# 이미지 요소가 나올 때 까지 대기할 시간(초)
wait_time = 10
# WebDriverWait 객체 생성
wait = WebDriverWait(driver, wait_time)
# 이미지 요소가 나타날 때까지 대기
images = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "._image._listImage")))
# 이미지가 존재하는 경우
if len(images) > 0:
for i, image in enumerate(images):
if i >= 10:
break
image.click()
time.sleep(2)
imgUrl = driver.find_element(By.XPATH, '/html/body/div[3]/div[2]/div/div[1]/section[2]/div/div[2]/div/div/div[1]/div[1]/div/div/div[1]/div[1]/img').get_attribute("src")
urllib.request.urlretrieve(imgUrl, f"image{i+1}.jpg")
for문과 enumerate() 함수를 이용하여 반복문을 만들어 주었습니다.
enumerate()함수는 반복문에서 현재 요소의 인덱스와 값을 동시에 사용하고자 할 때 유용하게 쓸 수 있습니다.
위에서는 i가 인덱스, image가 값이 되겠습니다.
따라서 코드블럭은 i(사진)가 10번째에 도달하면 break를 통해 빠져나옵니다.
첫번째 이미지를 클릭하고 안정적인 작업을 위해 대기시간 2초를 넣어주었습니다.
큰 이미지의 XPath로 요소를 찾고, 해당 요소의 "src" 속성 값을 가져옵니다.
urllib.request.urlretrieve() 함수를 사용하여 imgUrl에 지정된 이미지 URL을 다운로드하고, "image{i+1}.jpg"라는 이름으로 저장합니다.
'프로그래밍 실습 > Python' 카테고리의 다른 글
| 파이썬 셀레니움 이미지 크롤링 코드 총 정리 (python selenium image download code) (0) | 2023.06.08 |
|---|---|
| 파이썬 셀레니움 크롤링 (4) : while문을 이용하여 스크롤 끝까지 내리기 (0) | 2023.06.07 |
| 파이썬 셀레니움 크롤링 (3) : 네이버에서 이미지 검색하기 (0) | 2023.06.06 |
| 파이썬 셀레니움 크롤링 (2) : 크롬 브라우저 열기 (0) | 2023.06.06 |
| 파이썬 셀레니움 크롤링 (1) : 가상환경 세팅과 selenium 설치 (0) | 2023.06.04 |